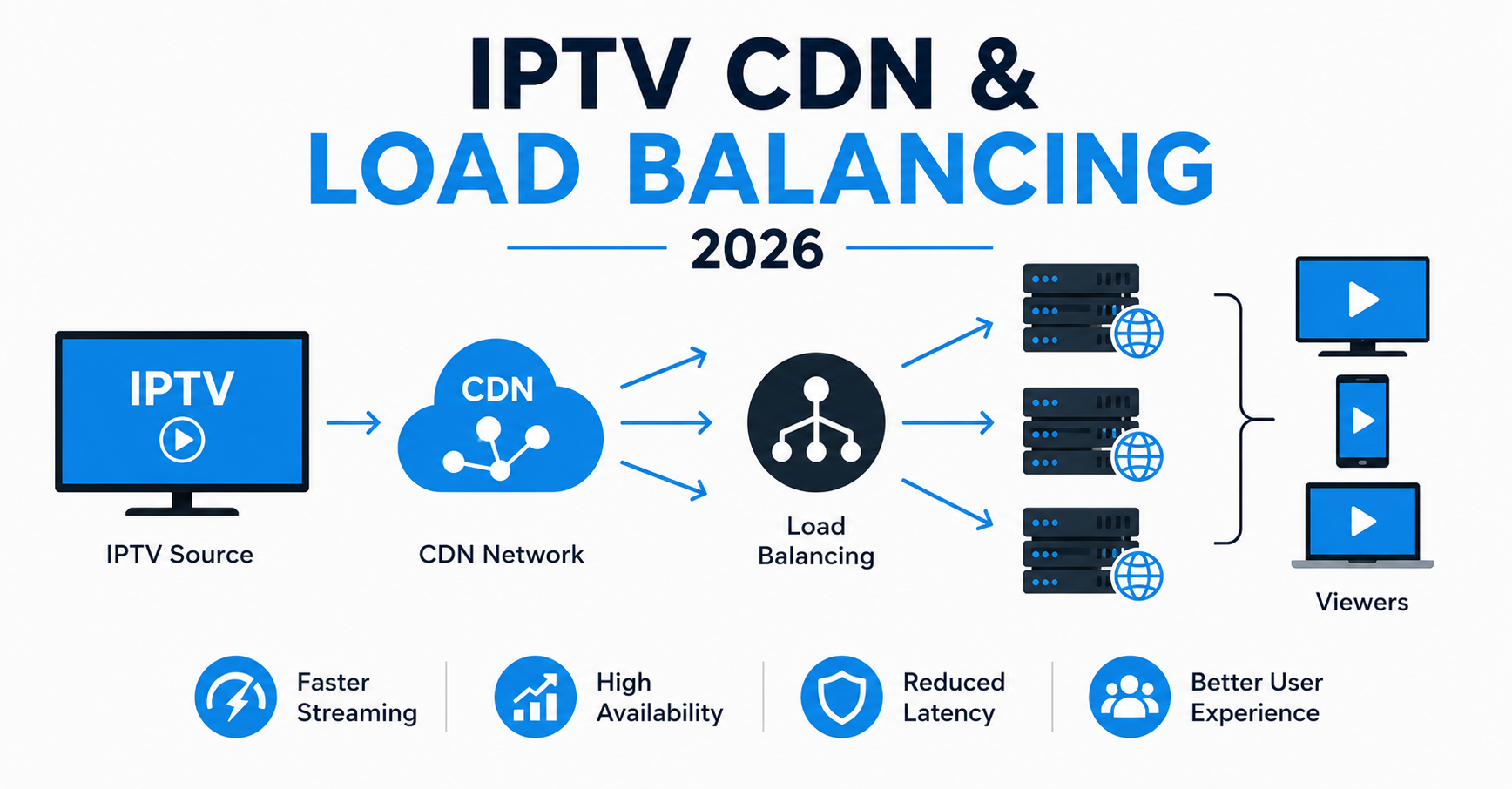
A single edge node can serve thousands of viewers right up until the moment a popular event starts. Then concurrency triples in ninety seconds, one region’s cache goes cold, and the player spinner appears for everyone at once. The stream did not “go down.” It got overwhelmed in a very specific, very predictable way, and almost every outage I have seen traces back to the same handful of design gaps.
Here is the short version before the detail. When a live IPTV stream stalls under heavy traffic, the cause is rarely the origin server itself. It is usually uneven request distribution, a missing failover path, or cache misses hammering the origin during a spike. The fix for live streaming CDN and load balancing in 2026 is not a bigger single server. It is distributing load across multiple edges, routing viewers to the nearest healthy node, and making sure a dead node fails over automatically instead of taking a region down with it.
That is the whole thesis. Everything below explains about Live Streaming CDN and Load Balancing 2026 why it happens and what to actually do about it.
The part most people get wrong about what a CDN does
A content delivery network is often described as “servers around the world that make things faster.” True, but incomplete, and the incomplete version is what causes bad architecture decisions.
For live streaming, the CDN’s real job is absorbing concurrency. A live event does not generate one request per viewer. It generates a request every few seconds per viewer, for every segment, for the entire duration. Ten thousand concurrent viewers on a stream with four second segments is roughly 2,500 segment requests every second, sustained. The CDN exists so those requests hit a cache near the viewer instead of stampeding back to your origin.
This is why live streaming CDN and load balancing in 2026 lives or dies on cache efficiency. If your cache hit ratio drops, every miss becomes an origin request, and the origin was never built to take that volume directly.
Pro Tip:
Watch your origin egress during a spike, not your CDN egress. A healthy live setup shows CDN traffic climbing sharply while origin traffic stays nearly flat. If origin traffic climbs in step with viewers, your cache is not doing its job and you are one popular event away from an outage.
Why “load balancing” means two completely different things here
People use the term loosely, and the looseness hides a real distinction. There are two layers, and confusing them leads to balancing the wrong thing.
The first layer is global, deciding which region or point of presence a viewer connects to. The second is local, deciding which specific server inside that region handles the request. Both matter, but they fail differently and you monitor them differently.
| Global load balancing | Local load balancing |
|---|---|
| Picks the region or POP | Picks the server within a POP |
| Driven by geography and health | Driven by connection and CPU load |
| Usually DNS or anycast based | Usually a reverse proxy or internal LB |
| Failure sends viewers to a far region | Failure overloads remaining nodes |
| Affects latency and routing | Affects per node capacity |
Get the global layer right and viewers land close to their content. Get the local layer right and no single box inside a region tips over while its neighbors sit idle. You need both. Most teams obsess over one and neglect the other.
The failure pattern nobody plans for until it bites
The most damaging outages are not total. They are partial, and partial failures are sneaky because your top level dashboard still looks green.
During one high concurrency event I watched, a single edge node in one region silently stopped serving segments while still answering health checks on its base path. The load balancer thought it was alive. Viewers routed to it got nothing. Twenty percent of an audience was effectively offline while the overview graph showed traffic flowing normally, because the other eighty percent masked it. The lesson stuck: a health check that only pings a homepage is not a health check for streaming. It has to request an actual segment and confirm a real response.
Pro Tip:
Make your health checks fetch a live media segment, not a status page. A node can serve a 200 on its root while its segment delivery is broken. Checking the thing viewers actually need is the difference between catching a partial failure in seconds versus reading about it in support tickets an hour later.
How geo-routing actually decides where you land
Geo-routing sounds simple. Send people to the closest server. In practice “closest” is doing a lot of hidden work, and getting it wrong adds latency nobody can explain.
Closest geographically is not the same as closest on the network. A viewer two hundred miles away on a well peered path will often get a faster, more stable stream than one fifty miles away whose traffic takes a strange route through another city first. Good routing weighs real network distance and current node health, not just a dot on a map. Anycast based routing helps here because the network itself steers traffic toward the nearest responsive entry point, and when a location goes dark, routes reconverge without a human touching anything.
This is where live streaming CDN and load balancing in 2026 has quietly matured. The routing decision now folds in live health signals, so a degraded node gets pulled from rotation before viewers feel it, rather than after.
A field checklist for surviving a traffic spike
When a known event is coming, the work happens before the spike, not during it. Reactive scaling during a live event is almost always too late, because the surge outruns the time it takes to add capacity.
- Pre warm caches in every region by pulling the stream through each POP before doors open
- Confirm origin has multiple upstream paths so one failed uplink does not isolate it
- Set health checks to segment level, with aggressive timeouts and fast removal of bad nodes
- Verify failover by deliberately killing a node in staging and watching traffic reroute
- Cap per node concurrency so the local balancer sheds load before a box saturates
- Have a tested origin shield or mid tier cache to absorb misses instead of passing them through
Skip the rehearsal and you will discover which item you missed at the worst possible moment, in front of your largest audience.
HLS latency and the tradeoff people forget
Lower latency feels universally good until you understand what you trade for it. Shorter segments cut delay but multiply request volume, and that volume lands squarely on your load balancing layer.
Standard HLS with longer segments is forgiving. Caches stay warm, request counts stay manageable, and the system tolerates a slow viewer connection by buffering ahead. Push toward low latency HLS with very short segments or partial segments and you slash the delay, but you also increase how often every viewer asks for something. More frequent requests mean tighter cache behavior, less buffer headroom, and far less tolerance for a node that hiccups. The architecture has to be more robust precisely because there is less slack in it.
There is no free lunch. Decide whether your audience needs near real time delivery or whether a few extra seconds of latency buys you a calmer, cheaper, more stable system.
Redundancy is not backups, it is parallel paths
A backup implies something you switch to after a failure. Real redundancy means the alternate path is already live and carrying weight, so failure is a routing change, not a recovery procedure.
This applies at every layer. Two origins in different locations, both active. Multiple CDN entry points rather than one. Several upstream IPTV network providers feeding your origin so a single carrier problem does not cut you off. The goal is that any one component can vanish and traffic simply flows around the gap. After enough postmortems, the pattern is unmistakable: the operators who stay up are the ones who designed for the missing piece in advance, while the ones who go dark were always one component away from an outage and did not know which one.
Pro Tip:
Test your redundancy by removing things on purpose during quiet hours. Pull a node, drop an origin, simulate a provider failure. Redundancy you have never exercised is a theory, and live events are a bad place to find out the theory was wrong.
Monitoring that tells you something before viewers do
The point of monitoring is lead time. You want to know a problem is forming while there is still room to act, not confirm one after the complaints arrive.
The signals that matter most for live delivery are cache hit ratio per region, origin request rate, per node concurrency, segment delivery error rate, and rebuffering reported from the player side. Player side data is underrated. Your servers can report healthy while real viewers are stalling, because the truth of the experience lives at the edge of the network, on the device. Pull metrics from the player and you see what people actually feel, not just what your infrastructure believes it is doing.
Frequently Asked Questions
What is Live Streaming CDN and Load Balancing 2026 in simple terms?
It is the combination of distributing your stream across many edge servers worldwide and intelligently routing each viewer to the nearest healthy one. The CDN absorbs the heavy, repeated segment requests a IPTV live event generates, while load balancing keeps any single server from being overwhelmed and reroutes traffic away from failures automatically.
Why does my live stream buffer when a lot of people watch at once?
Almost always because requests are unevenly distributed or your cache is missing too often, pushing load onto the origin. A spike triples concurrency fast, and if a region’s cache is cold or a node saturates, viewers there start rebuffering. Pre warming caches and capping per node load usually solves it.
Does live streaming CDN and load balancing in 2026 require a bigger origin server?
No, and that is the common mistake. A bigger single origin still fails under live concurrency because it becomes a single point of pressure. The answer is distribution and caching, so most requests never reach the origin at all, plus multiple active paths so no one component carries the whole load.
How is global load balancing different from local load balancing?
Global decides which region or point of presence a viewer connects to, based on location and health. Local decides which specific server inside that region handles the request, based on its current load. Global failures send people to distant regions. Local failures overload the remaining nodes in a region. You need both working.
What makes geo-routing send viewers to the wrong place?
Treating geographic distance as network distance. A closer server on a poorly peered path can be slower than a farther one with clean routing. Routing that ignores live node health also sends people to degraded servers. Good systems weigh real network paths and current health together, not just a location on a map.
How do I prepare infrastructure for a major live event?
Do the work before the spike. Pre warm caches in every region, confirm your origin has multiple upstream paths, set health checks to request real segments, and rehearse failover by killing a node in staging. Reactive scaling during the event is usually too late because the surge outruns the time needed to add capacity.
Why do partial outages go unnoticed for so long?
Because top level dashboards average everything together. If one node fails while others stay healthy, overall traffic still looks normal and masks the dead region. A health check that only pings a status page makes it worse, since a node can answer that while its segment delivery is broken. Segment level checks catch it fast.
Conclusion
Strong live streaming CDN and load balancing in 2026 comes down to a few disciplined habits rather than expensive hardware. Distribute the load so no single server carries an event alone. Route viewers by real network health, not just geography. Build redundancy as parallel active paths so failure becomes a routing change instead of a recovery scramble. And monitor from the player side so you learn about trouble before your audience does. The operators who stay online during the biggest spikes are simply the ones who designed for the failure in advance.
The deepest lesson from years of watching streams hold and break is almost dull in its simplicity. Capacity is not about the size of any one machine, it is about how gracefully the system behaves when one piece disappears. Build for the missing node, rehearse the failure while nobody is watching, and the live event takes care of itself.


